1. 추천시스템의 기본원리는 "과거는 곧 미래다." 추천을 위해 필요한 데이터는 유저들의 행위 behavior 기록이다. ex> 제품이나 컨텐츠에 대한 사용자의 선호/관심의 지표(상품 구매 이력, 이벤트 참석 이력, 평점 등의 유저 레이팅)
2. 추천시스템에서 사용되는 데이터는?
1) 명시적 레이팅(explicit rating)과 암묵적 점수(implicit feedback) in 유저 레이팅
- 명시적 레이팅은 평범/별점 등 구체적인 스케일로 점수를 매긴 것 - 암묵적 점수는 조회여부(0/1), 구매여부(0/1) 처럼 명시적으로 점수화하지 못하는 것 - 명시적 레이팅은 점수의 편향이 있거나, 존재하지 않는 경우가 암묵적 점수보다 더 많은 편 - 그래서 암묵적 점수를 더 많이 사용하는 추세
2) 추천시스템에서 해결해야할 가장 큰 문제는 데이터의 크기(data dimensionality) 문제
3. 추천 대상에 따른 추천시스템 분류
- 전체 추천: 불특정 다수에게 추천하는 형태 (ex: 검색엔진 사이트의 메인화면에서 보여지는 다수의 글/이미지/상품들, 추천 검색어, 실시간 검색어 등)
- 그룹 추천: 사용자들을 특정 세그먼트(그룹)으로 나누어서 각 그룹에 특화된 컨텐츠 추천하는 형태 (ex:성/연령별 선호 상품, 기사, 키워드)
- 개인추천(개인화): 개인의 과거 이력을 바탕으로 개인의 관심사를 특정하고 그에 맞는 아이템 추천하는 형태. "사용자를 어떻게 모델링(프로파일링) 할 것인가?"가 핵심
- 연관 아이템 추천: 맞춤추천이 아니라 개별 아이템별로 관련 아이템을 보여주는 형태 (ex: 최근 본 상품 탭, 유튜브 연관 동영상 등)
4. 추천 알고리즘에 따른 추천시스템 분류 - 협업 필터링(Collaborative Filtering)
1) 모델 기반 CF : 머신러닝 활용
2) 메모리 기반 CF : 유저-아이템 레이팅을 모두 메모리에 올려두고 유저-유저/아이템-아이템 관계(유사도)를 계산하기 때문에 메모리 기반이라고 불림
1> 제품-제품 협업 필터링: 사용가자 구매한 것과 가장 유사한 다른 제품 추천
2> 사용자-사용자 협업 필터링: 유사 사용자가 구매한 것과 가장 유사한 제품을 추천
*유사도(관계) 측정: 동시발생, 쟈카드 인덱스, 유클리디안 거리 등...
3) MF(Matrix Facrtorization) 방식 : 유저-아이템 레이팅을 메트릭스에서 고유벡터(eigen vector)를 구해 행렬을 분해하는 SVD(Singular value decomposition) 이용 -> 데이터의 크기(data dimensionality) 문제를 해결하기 위한 방법....이라는데 matrix 연산을 위한 메모리 감당이 어려움
- 컨텐츠 기반 필터링(Content-based Filtering) : 유저 프로파일 혹은 제품(컨텐츠) 프로파일 정보를 활용하여 추천
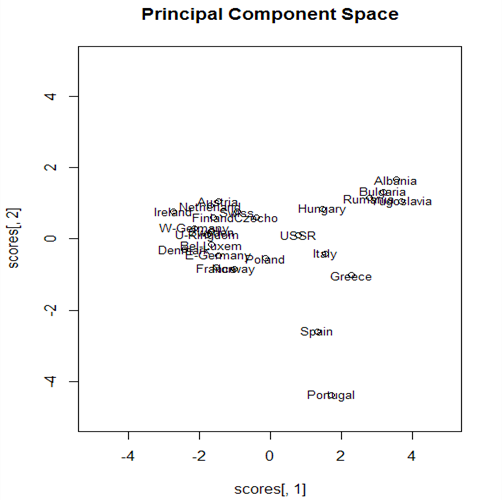
대다수의 나라들이 왼쪽에 군집을 이루가 있으나 오른쪽위에 알바니아, 불가리아, 루마니아, 유고슬라비아등 4개국이 진을 치고 있다. 관측개체 플롯내 위치와 변수 플롯의 곡류 위치가 대응하므로 이들 나라들은 곡류 섭취로 특성화된다. 아래 오른쪽에 스페인과 포르투갈이 있는데 이들은 생선, 콩, 과일 섭취로 특성화된다
5 functions to do Principal Components Analysis in R
17 Jun 2012
Principal Component Analysis (PCA) is a multivariate technique that allows us to summarize the systematic patterns of variations in the data.
From a data analysis standpoint, PCA is used for studying one table of observations and variables with the main idea of transforming the observed variables into a set of new variables, the principal components, which are uncorrelated and explain the variation in the data. For this reason, PCA allows to reduce a “complex” data set to a lower dimension in order to reveal the structures or the dominant types of variations in both the observations and the variables.
PCA in R
In R, there are several functions from different packages that allow us to perform PCA. In this post I’ll show you 5 different ways to do a PCA using the following functions (with their corresponding packages in parentheses):
prcomp() (stats)
princomp() (stats)
PCA() (FactoMineR)
dudi.pca() (ade4)
acp() (amap)
Brief note: It is no coincidence that the three external packages ("FactoMineR", "ade4", and "amap") have been developed by French data analysts, which have a long tradition and preference for PCA and other related exploratory techniques.
No matter what function you decide to use, the typical PCA results should consist of a set of eigenvalues, a table with the scores or Principal Components (PCs), and a table of loadings (or correlations between variables and PCs). The eigenvalues provide information of the variability in the data. The scores provide information about the structure of the observations. The loadings (or correlations) allow you to get a sense of the relationships between variables, as well as their associations with the extracted PCs.
The Data
To make things easier, we’ll use the dataset USArrests that already comes with R. It’s a data frame with 50 rows (USA states) and 4 columns containing information about violent crime rates by US State. Since most of the times the variables are measured in different scales, the PCA must be performed with standardized data (mean = 0, variance = 1). The good news is that all of the functions that perform PCA come with parameters to specify that the analysis must be applied on standardized data.
Option 1: using prcomp()
The function prcomp() comes with the default "stats"package, which means that you don’t have to install anything. It is perhaps the quickest way to do a PCA if you don’t want to install other packages.
# PCA with function prcomp
pca1=prcomp(USArrests,scale.=TRUE)# sqrt of eigenvalues
pca1$sdev
The function princomp() also comes with the default "stats" package, and it is very similar to her cousin prcomp(). What I don’t like of princomp() is that sometimes it won’t display all the values for the loadings, but this is a minor detail.
# PCA with function princomp
pca2=princomp(USArrests,cor=TRUE)# sqrt of eigenvalues
pca2$sdev
A highly recommended option, especially if you want more detailed results and assessing tools, is the PCA() function from the package "FactoMineR". It is by far the best PCA function in R and it comes with a number of parameters that allow you to tweak the analysis in a very nice way.
# PCA with function PCA
library(FactoMineR)# apply PCA
pca3=PCA(USArrests,graph=FALSE)# matrix with eigenvalues
pca3$eig
Another option is to use the dudi.pca() function from the package "ade4" which has a huge amount of other methods as well as some interesting graphics.
# PCA with function dudi.pca
library(ade4)# apply PCA
pca4=dudi.pca(USArrests,nf=5,scannf=FALSE)# eigenvalues
pca4$eig
Of course these are not the only options to do a PCA, but I’ll leave the other approaches for another post.
PCA plots
Everybody uses PCA to visualize the data, and most of the discussed functions come with their own plot functions. But you can also make use of the great graphical displays of "ggplot2". Just to show you a couple of plots, let’s take the basic results from prcomp().
Plot of observations
# load ggplot2
library(ggplot2)# create data frame with scores
scores=as.data.frame(pca1$x)# plot of observations
ggplot(data=scores,aes(x=PC1,y=PC2,label=rownames(scores)))+geom_hline(yintercept=0,colour="gray65")+geom_vline(xintercept=0,colour="gray65")+geom_text(colour="tomato",alpha=0.8,size=4)+ggtitle("PCA plot of USA States - Crime Rates")
Circle of correlations
# function to create a circle
circle<-function(center=c(0,0),npoints=100){r=1tt=seq(0,2*pi,length=npoints)xx=center[1]+r*cos(tt)yy=center[1]+r*sin(tt)return(data.frame(x=xx,y=yy))}corcir=circle(c(0,0),npoints=100)# create data frame with correlations between variables and PCs
correlations=as.data.frame(cor(USArrests,pca1$x))# data frame with arrows coordinates
arrows=data.frame(x1=c(0,0,0,0),y1=c(0,0,0,0),x2=correlations$PC1,y2=correlations$PC2)# geom_path will do open circles
ggplot()+geom_path(data=corcir,aes(x=x,y=y),colour="gray65")+geom_segment(data=arrows,aes(x=x1,y=y1,xend=x2,yend=y2),colour="gray65")+geom_text(data=correlations,aes(x=PC1,y=PC2,label=rownames(correlations)))+geom_hline(yintercept=0,colour="gray65")+geom_vline(xintercept=0,colour="gray65")+xlim(-1.1,1.1)+ylim(-1.1,1.1)+labs(x="pc1 aixs",y="pc2 axis")+ggtitle("Circle of correlations")